Hintergrund
Meine akademische Laufbahn begann mit einem Bachelorstudium der Grabungstechnik, in dem ich mich intensiv mit archäologischen Feldmethoden und der systematischen Datenaufnahme beschäftigte. Schon früh interessierte mich dabei die Frage, wie man die in der Archäologie typischerweise großen und komplexen Datenmengen durch standardisierte Verfahren effizienter erfassen, strukturieren und analysieren könnte. Dieses Interesse vertiefte ich im Rahmen meiner Bachelorarbeit durch die Entwicklung eines Workflows zur standardisierten Aufnahme und Ablage archäologischer Prospektionsdaten, unter anderem mithilfe einer PostgreSQL-Datenbank. Besonders faszinierend war für mich hierbei stets die Schnittstelle zwischen technischer Umsetzung und der nutzerfreundlichen Bedienbarkeit solcher Systeme, sodass auch technisch weniger versierte Anwender effektiv damit arbeiten können.
Die vorliegende Masterarbeit stellt die logische Fortsetzung dieser Interessen dar: Mithilfe der in den letzten Jahren erheblich weiterentwickelten und zunehmend leichter zugänglichen Methoden künstlicher Intelligenz soll ein System geschaffen werden, das durch moderne Large Language Models (LLMs) die intuitive Nutzung komplexer archäologischer Datenbanken ermöglicht – ohne vertiefte Kenntnisse der Datenbanksprache SQL.
Herausforderungen archäologischer Datenmengen und Komplexität
Archäologische Daten zeichnen sich durch ihre Menge und inhärente Komplexität aus: unterschiedliche Datenformate, hohe Kontextabhängigkeit und Unsicherheiten in der Interpretation erschweren eine systematische Nutzung und Auswertung. Zudem existieren oft weder einheitliche Standards noch angemessene Nutzeroberflächen, was den effektiven Zugang zu relevanten Informationen erschwert oder sogar unmöglich macht.
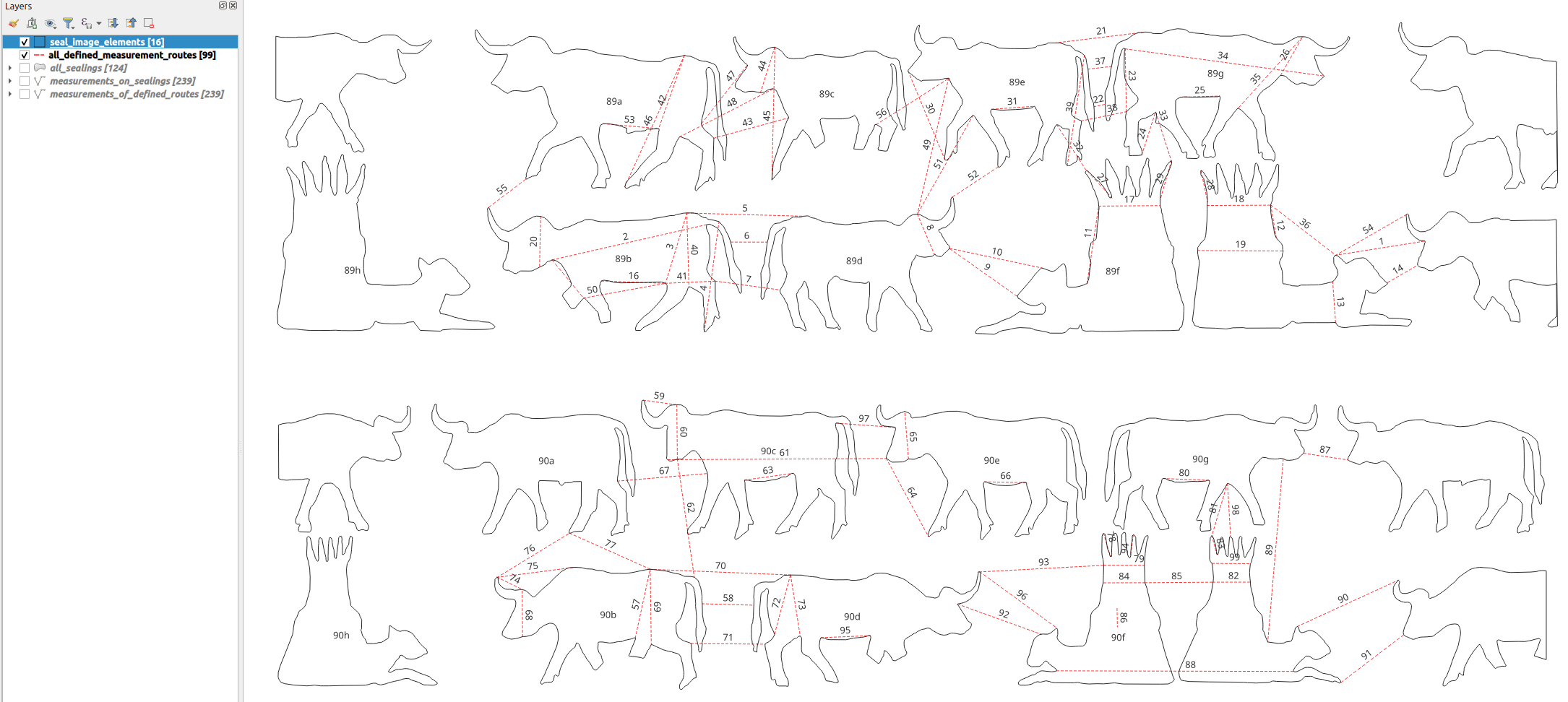
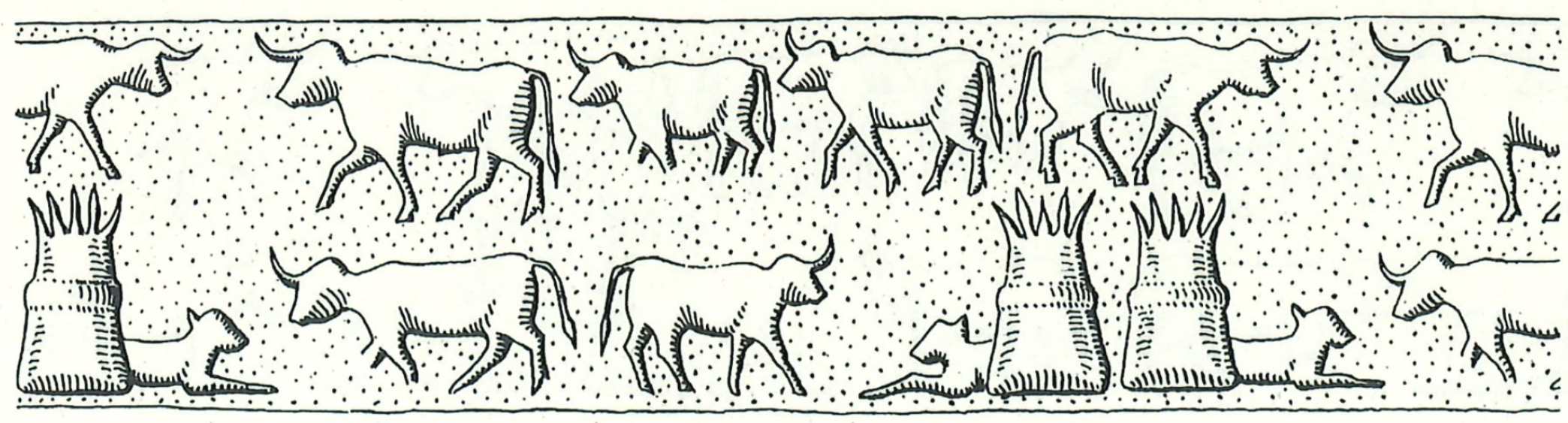
Die Masterarbeit greift konkret zwei Forschungsprojekte des Vorderasiatischen Museums Berlin auf: FRIMCLAY und States of Clay. Diese Projekte beschäftigen sich mit der systematischen Aufnahme und Analyse von Tonobjekten, insbesondere Siegelungen und Siegelbildern aus dem alten Mesopotamien. Dabei stehen Fragen der Dokumentation und strukturierten Interpretation dieser Artefakte im Vordergrund. Ein Schwerpunkt lag dabei auf der Digitalisierung dieser Siegelungen mittels Reflectance Transformation Imaging (RTI). Bei dieser Methode werden zahlreiche Aufnahmen aus verschiedenen Lichtrichtungen gemacht, um auch feinste Oberflächenstrukturen sichtbar zu machen und zu analysieren.
Im Zuge dieser Arbeiten wurde deutlich, dass die bestehenden Zuordnungen der Siegelungen zu rekonstruierten Siegelbildern teilweise unklar oder möglicherweise fehlerhaft sind. Um diese Zuordnungen objektiv und systematisch zu überprüfen sowie die tatsächliche Anzahl unterschiedlicher Siegelbilder besser bestimmen zu können, wurde eine umfassende Datenbank aufgebaut. Darin werden sowohl Detailinformationen zu einzelnen Abbildungselementen als auch exakte Messdaten gespeichert, was eine präzisere Auswertung und Interpretation ermöglicht. Genau hier setzt das in der Masterarbeit entwickelte System an, indem es mithilfe von KI-gestützten Abfragemöglichkeiten eine intuitive und effiziente Nutzung dieser komplexen Datenbank ermöglicht – auch für Fachanwender ohne tiefgehende Kenntnisse der Datenbanksprache SQL.
.jpg)
Potenziale moderner LLMs
Insbesondere seit den frühen 2010er Jahren hat sich das Feld der künstlichen Intelligenz grundlegend gewandelt: Aus ersten regelbasierten Systemen und flachen neuronalen Netzen entwickelte sich mit dem Aufkommen leistungsfähiger Hardware, neuer Trainingsmethoden und insbesondere der Transformer-Architektur eine neue Generation tiefer Lernsysteme. Spätestens mit dem Erfolg von ChatGPT wurde auch in der breiten Öffentlichkeit deutlich, dass LLMs nicht nur natürlichsprachliche Texte verstehen und erzeugen können, sondern sich auch für komplexe Aufgaben wie Programmieren, Übersetzen oder Datenbankabfragen eignen.
Für den Kontext dieser Arbeit besonders vielversprechend ist dabei das Anwendungsfeld Text-to-SQL: Speziell dafür trainierte LLMs können hier natürlichsprachliche Anfragen automatisch in strukturierte SQL-Abfragen übersetzen. Diese Technologie ermöglicht es auch Fachanwendern ohne tiefere technische Kenntnisse, komplexe Datenbankrecherchen durchzuführen – ein enormes Potenzial gerade für datenintensive Disziplinen wie die Archäologie.
Datenmodellierung und Datenbankarchitektur
Zur systematischen Verwaltung der archäologischen Forschungsdaten wurde im Rahmen dieser Masterarbeit eine relationale PostgreSQL-Datenbank entwickelt, die den besonderen Anforderungen an Unsicherheiten, Mehrdeutigkeiten und Mehrschichtigkeit gerecht wird. Grundlage war eine klare konzeptuelle Trennung zwischen Siegelung und Siegelbild, ergänzt um deren jeweilige Bestandteile wie Abbildungselemente und Messstrecken. Die Datenbank bietet durch die Möglichkeit der Vergabe von Konfidenzwerten und Beziehungen eine differenzierte Erfassung sowohl gesicherter als auch hypothetischer Zuordnungen.
.png)
Zusätzlich wurde ein GIS-basiertes Visualisierungssystem realisiert, das interne Strukturen schematisch und vergleichbar abbildet.