Umsetzung
Nach der Auswahl eines geeigneten Modells und der Definition zentraler Optimierungsstrategien wurde ein eigenes Text-to-SQL-System entwickelt, das gezielt auf die Anforderungen archäologischer Forschungsdatenbanken ausgerichtet ist. Das System besteht aus einem klar getrennten Frontend und Backend und ermöglicht eine direkte, lokale Anbindung an eine PostgreSQL-Datenbank.
Ziel der Umsetzung war es, ein leichtgewichtiges, transparentes und erweiterbares System zu schaffen, das vollständig offline betrieben werden kann. Der Fokus lag dabei auf einer möglichst direkten Interaktion mit dem LLM sowie einer präzisen Steuerung der Eingabe- und Ausgabestrukturen. Neben einer API zur Kommunikation zwischen Modell und Datenbank wurde auch eine benutzerfreundliche Oberfläche zur Abfrageformulierung und Ergebnisanzeige entwickelt.
Promptdesign und Modellinteraktion
SQLCoder ist ein Sprachmodell, das speziell darauf trainiert wurde, SQL-Abfragen aus natürlichsprachigen Eingaben zu erzeugen. Es arbeitet promptbasiert und erwartet eine klar strukturierte Eingabe, die bestimmte Platzhalter bzw. Abschnitte enthält. Die verwendete Promptstruktur ist rechts dargestellt.
Die gezeigte Promptstruktur enthält mehrere Platzhalter, die gezielt befüllt werden müssen – einerseits mit der konkreten Nutzerfrage, andererseits mit strukturierten Kontextinformationen zur angebundenen Datenbank. Letztere wurden im Rahmen dieser Arbeit systematisch aufbereitet und eingebunden: Neben einer detaillierten DDL-Darstellung (Schema-Linking) wurden auch gezielte Abfragebeispiele (Few-Shot Learning) integriert. Da das Modell lokal ausgeführt wurde und der verfügbare VRAM begrenzt war, musste zudem eine umfangreiche Token-Minimierung erfolgen, um alle relevanten Informationen innerhalb der maximalen Eingabelänge unterzubringen.

Als Ausgabe erzeugt SQLCoder stets den vollständigen Prompt mitsamt allen eingebetteten Informationen – ergänzt um die darauf basierende, vom Modell generierte SQL-Abfrage.
Semantische Klarheit durch Natural Views
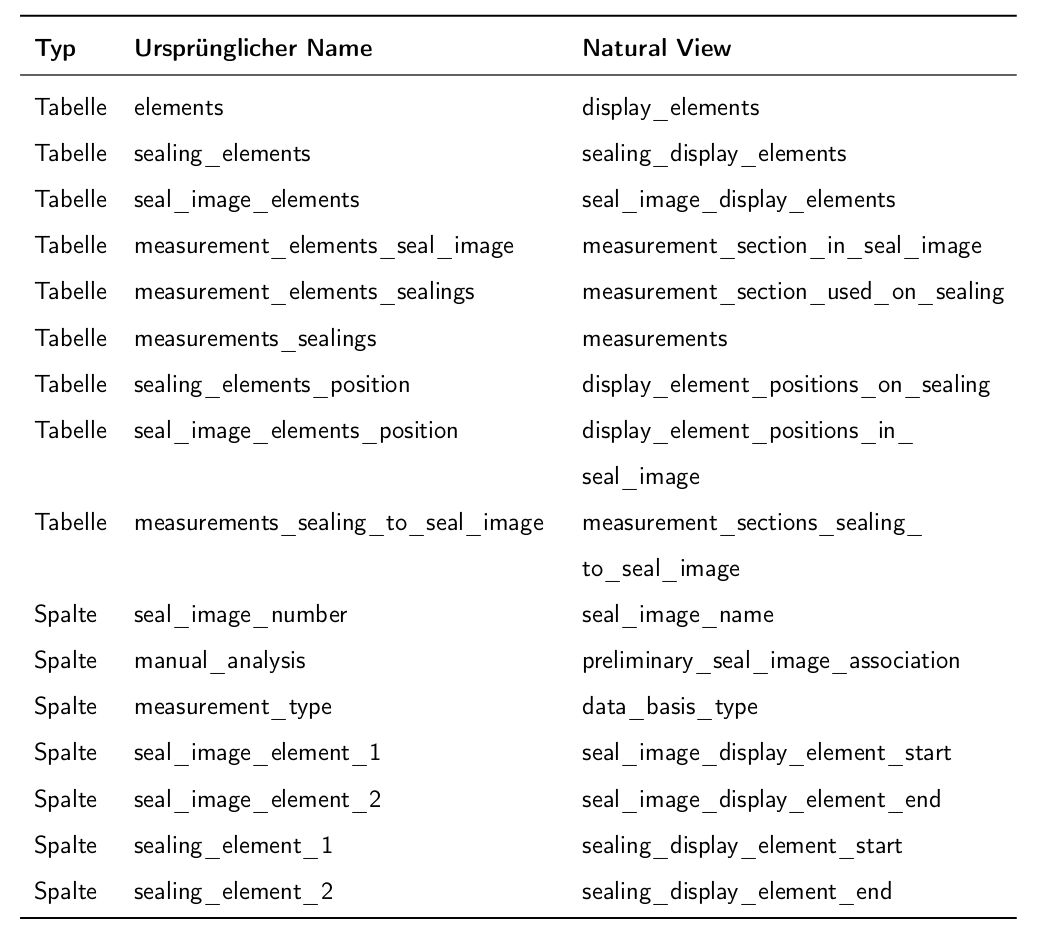
Um Fehlinterpretationen bei der SQL-Generierung zu vermeiden, wurden im Projekt sogenannte Natural Views eingeführt: ursprüngliche Tabellen- und Spaltennamen wurden durch sprechendere Bezeichnungen ersetzt, die den tatsächlichen Inhalt besser widerspiegeln. Diese rein dokumentationsbasierte Umbenennung verbessert die Verständlichkeit der Datenstruktur für das Sprachmodell. Die Abbildung links zeigt eine Auswahl der ersetzten Benennungen.
Systemarchitektur im Überblick
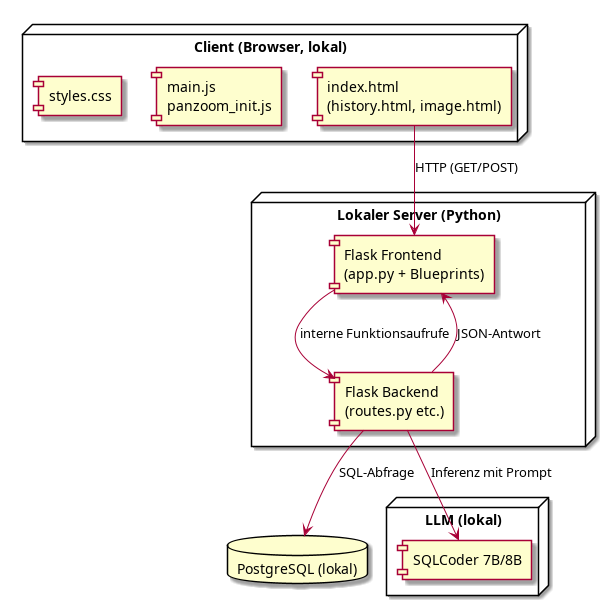
Das System besteht aus einem lokal betriebenen Client-Server-Setup. Die Benutzeroberfläche läuft im Browser, während das Backend auf einem lokalen Python-Server (Flask) ausgeführt wird. Dort werden Anfragen verarbeitet, an das LLM übergeben und Ergebnisse aus einer PostgreSQL-Datenbank zurückgegeben. Die Architektur ermöglicht eine datensouveräne, offline-fähige Anwendung ohne externe Dienste.
Rechts ist das Gesamtsystem in einem Deploymentdiagramm abgebildet.
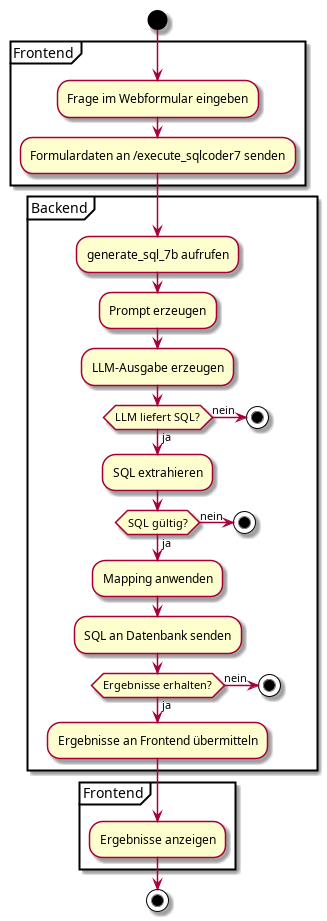
Ablauf einer Benutzeranfrage
Der Ablauf einer Benutzeranfrage beginnt mit der Eingabe einer natürlichsprachigen Frage im Webformular. Das Backend verarbeitet die Anfrage, ruft das Sprachmodell lokal auf und extrahiert die SQL-Abfrage. Diese wird überprüft, rekonvertiert, an die Datenbank gesendet und das Ergebnis wieder zurückgegeben. Das Sequenzdiagramm zeigt diesen Ablauf Schritt für Schritt.
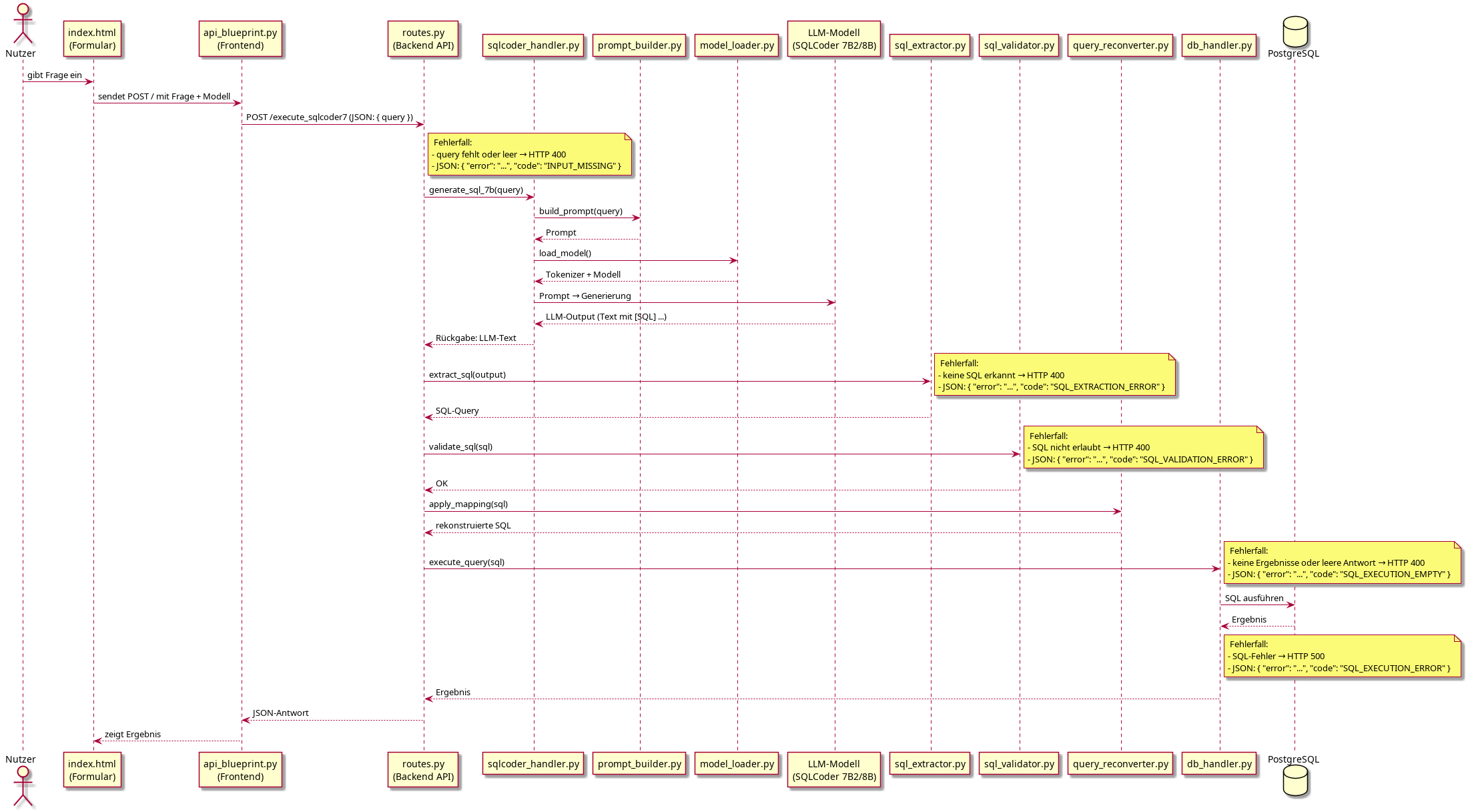
Systemlogik und Komponenten
Die Architektur folgt dem Prinzip klar getrennter Verantwortlichkeiten. Im Backend übernimmt jedes Modul eine spezifische Aufgabe: Prompt-Erstellung, Modellaufruf, SQL-Extraktion, Validierung und Datenbankkommunikation. Das Frontend wiederum steuert Navigation, Visualisierung und Interaktion. Die Diagramme zeigen die aufgeteilten Komponenten im Überblick.
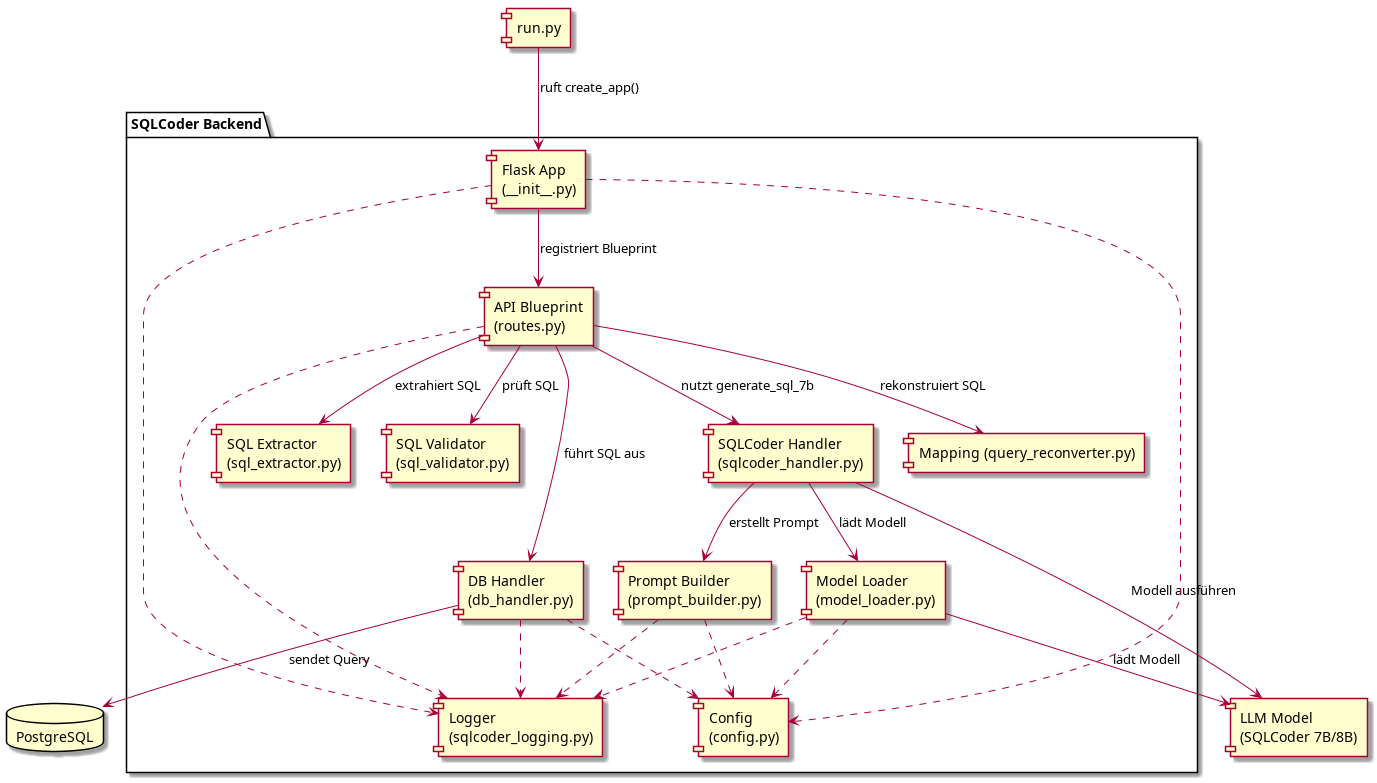
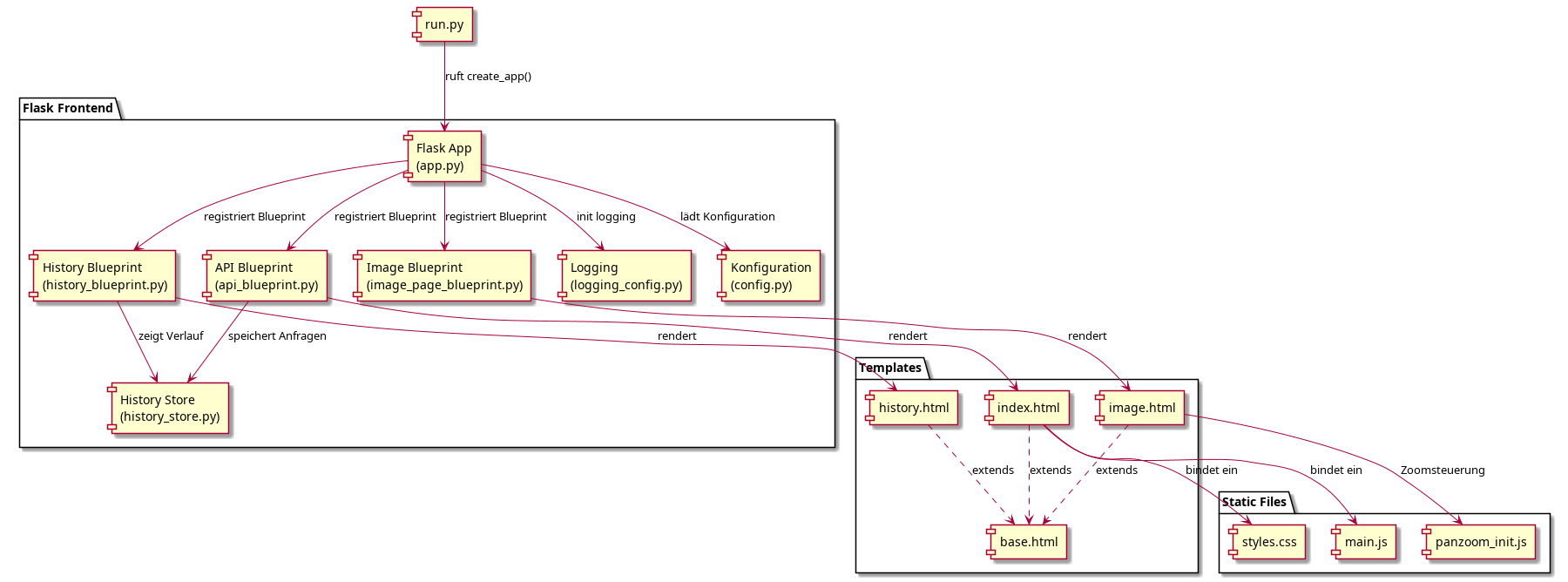
Dateistruktur und Quellcode-Organisation
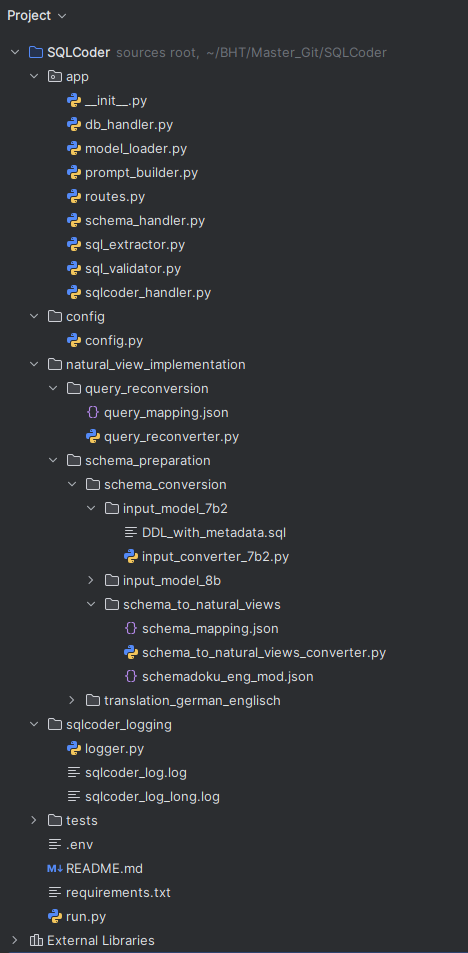
Die Projektstruktur spiegelt die Modularität auch im Quellcode wider. Das Backend trennt API, Modellintegration und Validierung in eigene Module. Auch das Frontend folgt einer klaren Trennung zwischen Templates, CSS/JS und Blueprints. Diese Struktur unterstützt Wartbarkeit und Erweiterbarkeit – etwa für den Einsatz weiterer LLMs oder die Anbindung alternativer Datenquellen.
Das vollständige Projekt inklusive dem kompletten Code ist unter https://gitlab.com/MaeTyy/master einsehbar.
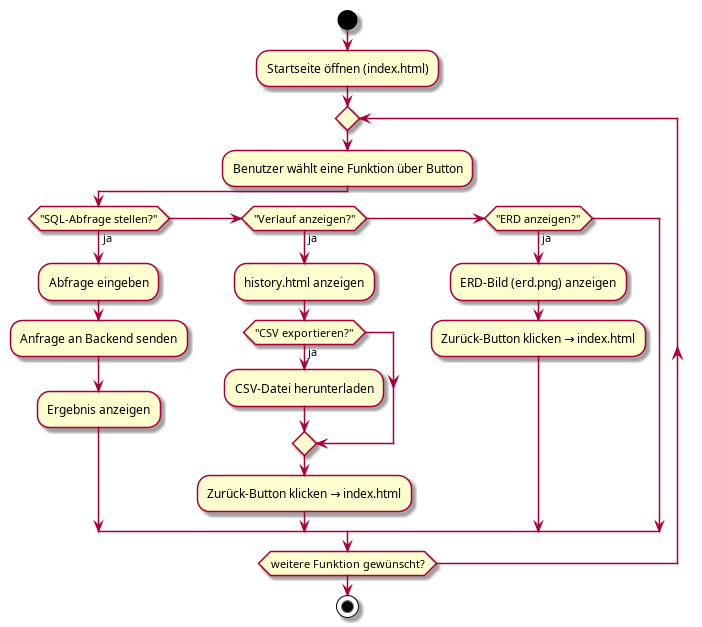
Abläufe im Frontend und Backend
Zur weiteren Verdeutlichung wurden Aktivitätsdiagramme erstellt, die die Abläufe im Backend (Schrittfolge der Anfrageverarbeitung) sowie im Frontend (Navigation, Button-Logik) dokumentieren. Diese verdeutlichen die Robustheit der Steuerungslogik und den Umgang mit Fehlerfällen.