Modellauswahl
Für die Entwicklung des Systems war es notwendig, ein geeignetes LLM auszuwählen, das die automatische Übersetzung von Nutzereingaben in SQL-Abfragen ermöglicht. Um diese Auswahl fundiert und nachvollziehbar treffen zu können, wurde zunächst ein Katalog an Kriterien definiert, die zentrale Anforderungen an das Modell im Kontext speziell dieser Masterarbeit abbilden.
Anschließend wurden verschiedene aktuelle Text-to-SQL-Ansätze und konkrete Modellimplementierungen anhand dieser Kriterien miteinander verglichen. Auf Basis dieser Analyse konnte eine begründete Modellauswahl für die Umsetzung getroffen werden.
Zusätzlich zur Modellauswahl musste entschieden werden, welche Optimierungsstrategien geeignet sind, um die Ergebnisqualität des gewählten Modells weiter zu verbessern.
Kriterien zur Modellauswahl
Es wurden insgesamt fünf relevante Kriterien definiert. Diese sind in der nachfolgenden Tabelle übersichtlich zusammengefasst.

Modellvergleich & Auswahlprozess
Im Rahmen dieser Masterarbeit wurden elf verschiedene Systeme aus dem Bereich Text-to-SQL vorgestellt und auf Grundlage der definierten Kriterien analysiert. Dabei wurden sowohl vollständige Softwarelösungen als auch für sich stehende aus Text-to-SQL optimierte LLM berücksichtigt. Nachfolgend findet sich eine tabellarische Übersicht dieser elf Ansätze, farblich mithilfe eines Ampleschemas bewertet.
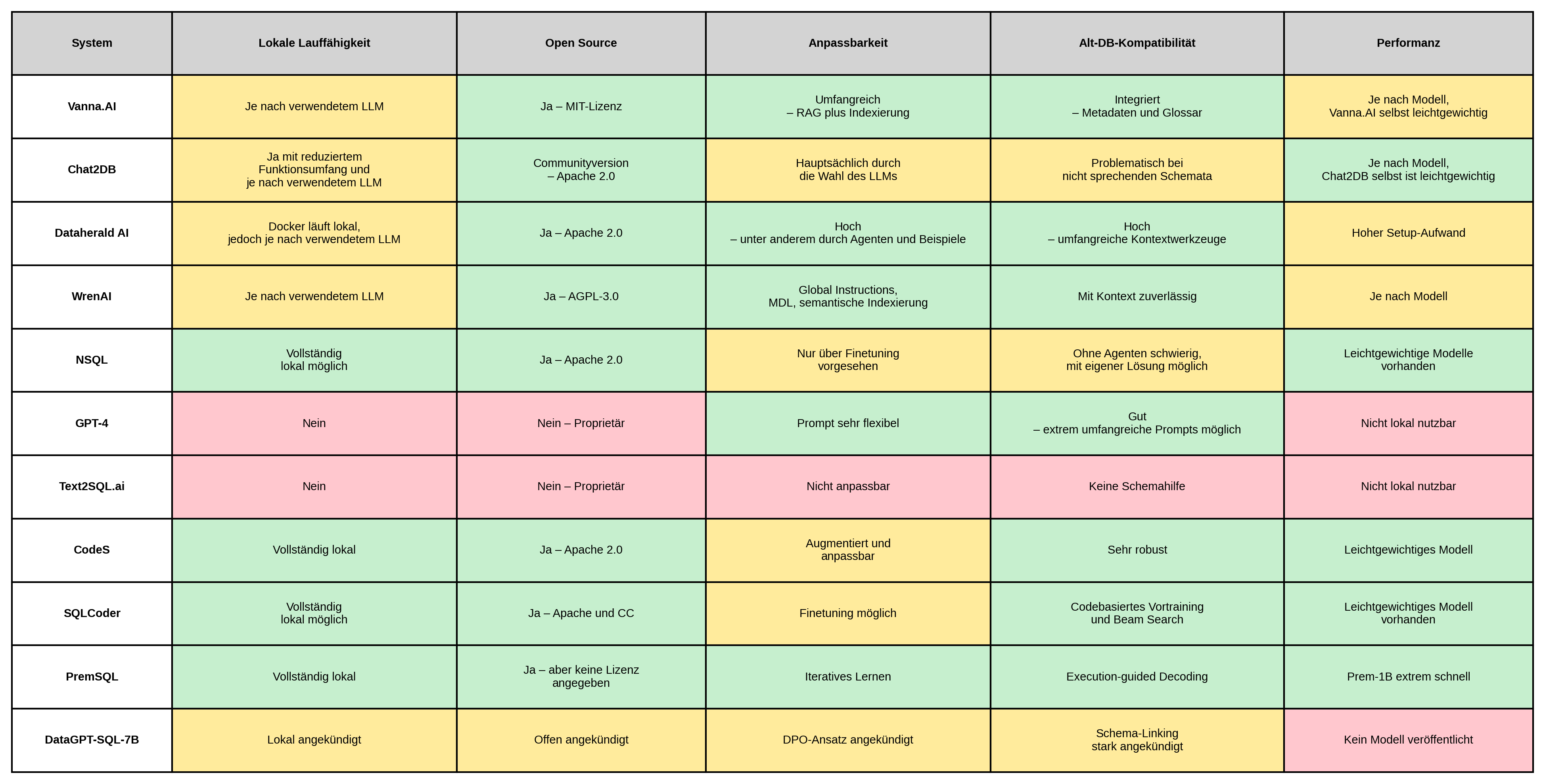
Im Verlauf der Analyse wurde entschieden, kein bestehendes Frontend- oder Agentensystem zu übernehmen, sondern ein eigenes, möglichst nah am LLM entwickeltes System zu realisieren. Damit sollte maximale Flexibilität erreicht und ein vertieftes Verständnis für die Funktionsweise von Text-to-SQL-Anwendungen gewonnen werden.
Diese Kriterien führten zu einer Eingrenzung auf vier vielversprechende Kandidaten: NSQL, CodeS, PremSQL und SQLCoder. Alle vier erfüllen die grundlegenden Anforderungen an Offenheit, Anpassbarkeit und technische Eigenständigkeit – und boten somit eine geeignete Basis für eine eigenentwickelte Lösung.
In der anschließenden vertieften Bewertung zeigte sich SQLCoder als die überzeugendste Wahl. Das Modell ließ sich schnell und unkompliziert in die lokale Entwicklungsumgebung integrieren, ist aktiv gepflegt und breit verfügbar (z. B. über Hugging Face), und besitzt eine fundierte Dokumentation sowie eine aktive Entwickler-Community. Im Vergleich dazu erwiesen sich NSQL und CodeS als weniger gut dokumentiert und schwächer verbreitet, während PremSQL in der Umsetzung hohe Einstiegshürden und komplexe Modellanpassungen erforderte.
Aus diesen Gründen wurde SQLCoder als zentrale Modellbasis für das im Rahmen dieser Arbeit entwickelte System ausgewählt.
Wahl geeigneter Optimierungsstrategien
Für die Optimierung der Ausgabe eines LLM basierten Text-to-SQL Systems gibt es verschiedene gängige Strategien. Die Wichtigsten sind in der nachfolgenden Tabelle zusammengefasst.
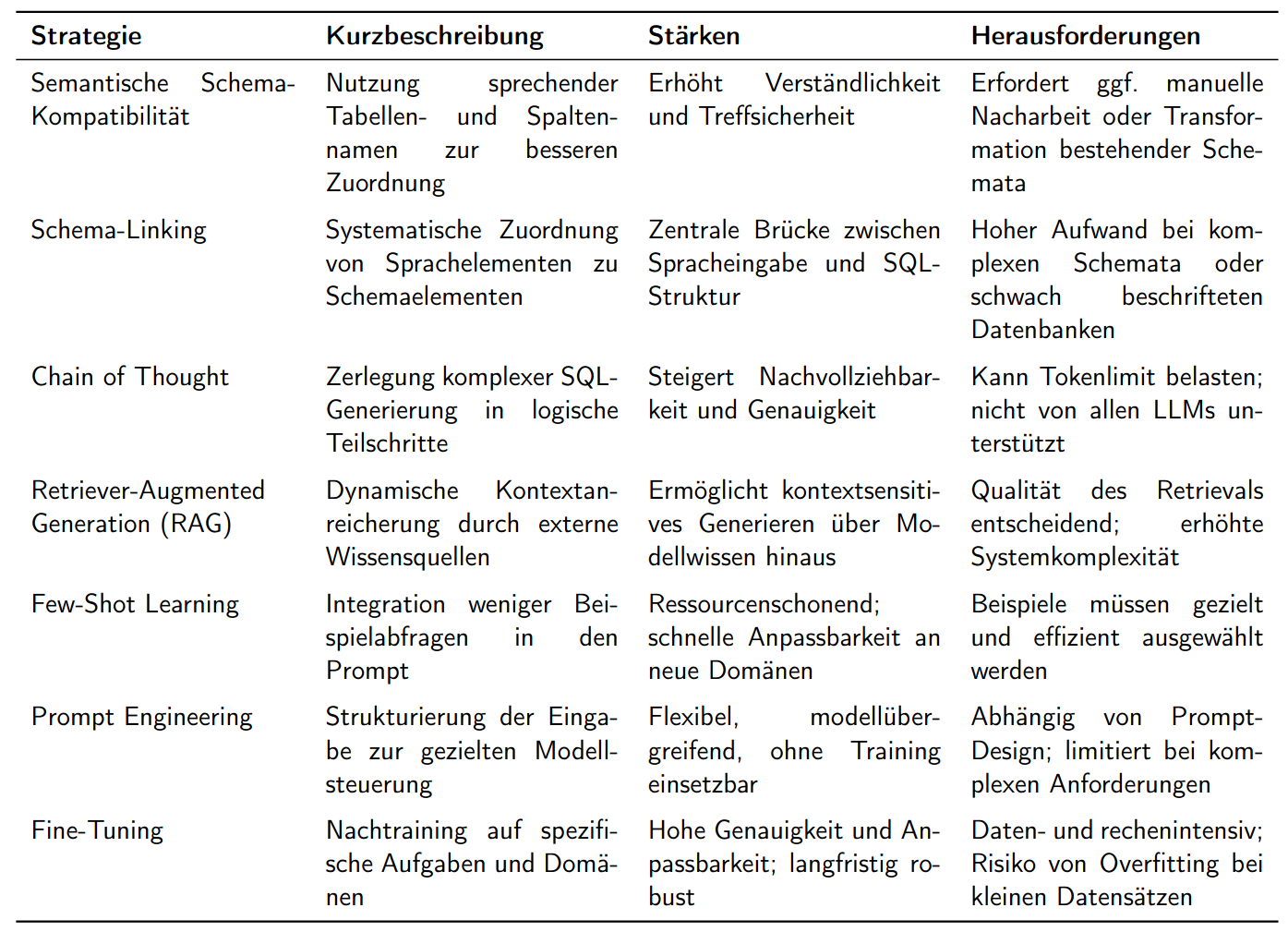
Die Auswahl geeigneter Optimierungsstrategien erfolgte anhand der spezifischen Anforderungen der eingesetzten Datenbank und des verwendeten Modells. Aufgrund vieler nicht sprechender und ähnlicher Tabellen- und Spaltennamen wurde der Fokus auf Maßnahmen gelegt, die die semantische Verständlichkeit und strukturelle Klarheit für das LLM erhöhen.
Zentral ist dabei die Optimierung der semantischen Schema-Kompatibilität, unterstützt durch eine gezielte Schemadokumentation in verständlicher Sprache. Ergänzt wird dies durch Schema-Linking, das die strukturierte Zuordnung von Spracheingaben zu Datenbankelementen im Prompt sicherstellt. Beide Maßnahmen bilden die Grundlage für eine robuste SQL-Generierung durch SQLCoder.
Zudem wurde Few-Shot Learning integriert, um durch wenige domänenspezifische Beispiele im Prompt kontextuelles Modellverhalten zu fördern – ohne den Aufwand eines vollständigen Fine-Tunings. Letzteres wurde bewusst ausgeschlossen, da es angesichts begrenzter Trainingsdaten und Ressourcen nicht praktikabel war.
Insgesamt fußt die Optimierung auf einem durchdachten Prompt Engineering, das verschiedene Techniken kombiniert und eine flexible, ressourcenschonende Anpassung des Modells an die Anforderungen archäologischer Datenbanken ermöglicht.